
GLM-ASR-Nano-2512
👋 Join our WeChat community
{kind=link}
Model Introduction
GLM-ASR-Nano-2512 is a robust, open-source speech recognition model with 1.5B parameters. Designed for real-world complexity, it outperforms OpenAI Whisper V3 on multiple benchmarks while maintaining a compact size.
Key capabilities include:
Exceptional Dialect Support: Beyond standard Mandarin and English, the model is highly optimized for Cantonese (粤语) and other dialects, effectively bridging the gap in dialectal speech recognition.
Low-Volume Speech Robustness: Specifically trained for "Whisper/Quiet Speech" scenarios. It captures and accurately transcribes extremely low-volume audio that traditional models often miss.
SOTA Performance: Achieves the lowest average error rate (4.10) among comparable open-source models, showing significant advantages in Chinese benchmarks (Wenet Meeting, Aishell-1, etc..).
Benchmark
We evaluated GLM-ASR-Nano against leading open-source and closed-source models. The results demonstrate that * GLM-ASR-Nano (1.5B)* achieves superior performance, particularly in challenging acoustic environments.
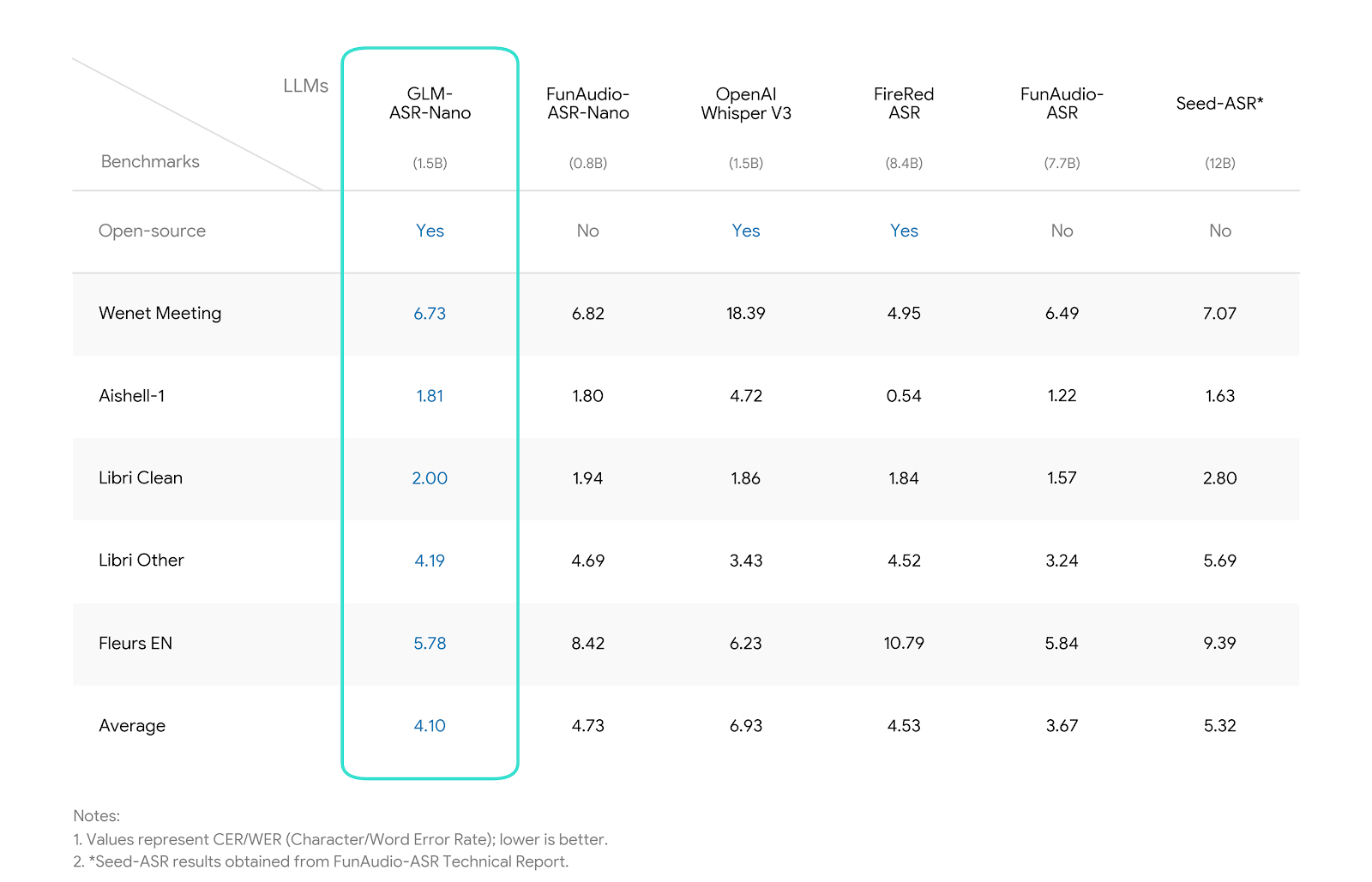
Notes:
- Wenet Meeting reflects real-world meeting scenarios with noise and overlapping speech.
- Aishell-1 is a standard Mandarin benchmark.
Inference
GLM-ASR-Nano-2512 can be easily integrated using the transformers library.
We will support transformers 5.x as well as inference frameworks such as vLLM and SGLang.
you can check more code in Github.
- Downloads last month
- 571